GitHub リポジトリ: https://github.com/AtsushiYanaigsawa768/Compass
HuggingFace Collection: https://huggingface.co/collections/Yana/compass
Poster: ft-lllm-2025-poster.pdf (Japanese)
Slide: ft-llm-2026-slide.pdf (Japanese)
本プロジェクトは FT-LLM 2026 の自由形タスクとして実施されたものである。
題目: 推論強化と文書読解の統合による日本語金融VLMの開発 (Development of a Japanese Financial VLM through Integration of Reasoning Enhancement and Document Comprehension)
はじめに
日本の金融業界では、有価証券報告書、決算短信、金融庁や財務省への規制提出書類など、大量の構造化・半構造化文書が生成されている。これらの文書の自動理解には、数値データと文章が混在する複雑な表レイアウト、日英混合表記、ROE・WACC・前年比成長率などの金融概念に対する多段階の数値推論といった固有の課題がある。
近年のVision-Language Model(VLM)は、汎用的な視覚質問応答や文書理解タスクにおいて高い性能を示している [1] が、日本語金融文書への適用は依然として限定的である。汎用VLMは金融表の解釈や正確な数値計算に必要なドメイン固有の推論能力を欠いており、また既存モデルの多くは英語コンテンツに最適化されている。
本研究では、これらの課題に対処する日本語金融VLM Compass を提案する。Compassは、(1) 基盤レベルの視覚-言語アライメント、(2) 知識蒸留による数学的推論強化、(3) 文書画像の直接的な視覚読解による金融ドメイン特化の三段階学習パイプラインを統合する。本モデルはLLaVA-OneVisionアーキテクチャ [1] を基盤とし、言語バックボーンにllm-jp-4-8bを採用するなど、日本語金融ドメインに向けた複数の主要な適応を行っている。
本研究の主な貢献は以下の通りである:
- 視覚-言語アライメント、構造化された数学的推論、金融ドメイン専門知識を段階的に構築する三段階学習パイプライン。
- Qwen3-30B-A3B-Thinking-2507 [2] からのXML構造の出力フォーマットを用いた知識蒸留により、約75万件の数学問題に対する段階的推論能力を獲得。
- 日本政府PDF文書(内閣府、金融庁、財務省)からのPhase 1(OCRおよび視覚QAデータ)とPhase 3(多難易度の質問生成と整合性検証を含む金融ドメインQA)の両方における文書理解データセットの構築。これらのデータセットはHuggingFaceで公開されており、本研究の主要な貢献の一つである。
- 日本政府金融PDF文書に対する4段階の難易度の金融質問応答を用いた直接的な視覚文書読解。
アーキテクチャ
CompassはLLaVA-OneVision [1] で確立された三要素VLMアーキテクチャに従い、視覚エンコーダ、MLPプロジェクタ、大規模言語モデルから構成される。日本語金融文書理解に適した個別のコンポーネントを採用した。
視覚エンコーダ
視覚エンコーダとして SigLIP-v2 SO400M-patch14-384 [6, 15] を採用する。本モデルは隠れ次元1,152の特徴表現を生成し、1画像あたり729パッチ(384 x 384の入力解像度、パッチサイズ14から27 x 27の空間グリッド)を出力する。
MLPプロジェクタ
視覚-言語プロジェクタは、視覚エンコーダの出力を言語モデルの埋め込み空間にマッピングする2層MLPである:
Linear(1152 → 4096) → GELU → Linear(4096 → 4096)
プロジェクタは約800万の訓練可能パラメータを持ち、視覚表現と言語表現の間の主要な橋渡しとなる。
言語モデル
言語バックボーンとして llm-jp-4-8b を採用する。これは隠れ次元4,096の80億パラメータ日本語言語モデルである。VicunaやLLaMAベースのモデルを使用するオリジナルのLLaVA-OneVisionからの重要な変更点であり、llm-jp-4-8bは日本語テキストコーパスに対する強力な事前学習により、日本語金融文書理解のより適切な基盤を提供する。
LLaVA-OneVisionとの主な違い
LLaVA-OneVisionとは異なり、CompassはAnyResマルチ解像度処理戦略を採用していない。LLaVA-OneVisionがAnyRes-9(1つのグローバルクロップ + 最大8つのローカルクロップ、1画像あたり6,561視覚トークンを生成)を使用するのに対し、Compassは各入力画像を単一の384 x 384クロップとして処理し、1画像あたり729視覚トークンを生成する。この設計により計算コストを削減しつつ、文書理解タスクに十分な解像度を維持している。
| 項目 | LLaVA-OneVision | Compass |
|---|---|---|
| マルチ解像度 | AnyRes-9(6,561トークン/画像) | 単一クロップ(729トークン/画像) |
| Stage 1-1 エポック数 | 1 | 2(小規模データセットの補償: 330K vs 558K) |
| Stage 1-2 LLM学習 | フルファインチューニング | LoRA(r=64, alpha=128) |
| 実効バッチサイズ(Stage 1-1) | 256 | 128 |
学習パイプライン
本学習パイプラインは三つのフェーズで構成され、各フェーズは前フェーズで確立された能力の上に構築される。以下の表に、各学習段階におけるモジュールの学習状態をまとめる:
| フェーズ | ステージ | Vision Encoder | MLP Projector | LLM | 目的 |
|---|---|---|---|---|---|
| Phase 1 | Stage 1-1 | 凍結 | 学習 | 凍結 | 視覚-言語アライメント |
| Phase 1 | Stage 1-2 | 学習 | 学習 | LoRA (r=64) | 視覚的指示理解 |
| Phase 2 | SFT | — | — | QLoRA (r=32) | 構造化推論 |
| Phase 3 | Stage 3-1 | — | — | LoRA (r=16) | 金融テキストQA |
| Phase 3 | Stage 3-2 | 凍結 | 学習 | LoRA (r=16) | 金融文書読解 |
凍結 = パラメータ固定、学習 = パラメータ更新、— = モジュール不使用
Phase 1: 基盤VLM構築
Phase 1では、基本的な視覚-言語アライメントと視覚指示理解能力を確立する。データセット作成の詳細な手順については、リポジトリの Phase 1 README を参照されたい。
Stage 1-1: キャプション・OCR事前学習
本ステージの目的は、MLPプロジェクタを訓練して視覚特徴と言語モデルの埋め込み空間をアライメントし、基本的な視覚-言語対応を確立することである。
学習構成: MLPプロジェクタのみ更新。視覚エンコーダと言語モデルは凍結。
データセット:
- STAIR Captions (shunk031/STAIR-Captions) [3]:約33万件の日本語画像-キャプションペア(license_id=4でフィルタリング)。各画像に5つのキャプションが付与されており、各学習エポックでランダムに1つのキャプションを選択することでデータの多様性を増加。
- OCRデータセット (Yana/ft-llm-2026-ocr-dataset):LLaVAR [12] を参考に、Qwen3-VL-32Bを用いて4種類のOCRプロンプトで日本政府PDF文書から生成。本データセットにより、モデルは文書画像からテキストを読み取る能力を獲得する。本研究で構築したデータセット。
学習プロンプト: 各サンプルはキャプションデータに対して指示文 "この画像を端的に説明してください。" を使用し、対応するキャプションを目標応答とする。
ハイパーパラメータ: 学習率1e-3、AdamWオプティマイザ、3%ウォームアップ付きコサイン学習率スケジューラ、実効バッチサイズ128(デバイスあたりバッチサイズ2、勾配累積64)、2エポック、最大系列長2,048、bf16混合精度。損失関数は応答トークンのみに対する交差エントロピー損失(次トークン予測)。
Stage 1-2: 視覚指示チューニング
本ステージでは、三つの全コンポーネントを訓練することで、モデルの視覚指示理解・追従能力を獲得する。
学習構成: 視覚エンコーダ、MLPプロジェクタ、言語モデル(LoRA経由)の全てを更新。視覚エンコーダは事前学習済み視覚特徴を保持するため低い学習率2e-6を使用し、プロジェクタとLLM LoRAは2e-5を使用。
データセット:
- QAデータセット (Yana/ft-llm-2026-qa-dataset):Qwen3-VLによる二段階プロセスで生成されたQAペア。まず抽出型QA(De)、次に推論型QA(Dr)を、政府PDF文書のページから生成。フォーマットはLLaVAR-2 [11] を参考にした。本研究で構築したデータセット。
- ja-vg-vqa-conversation (llm-jp/ja-vg-vqa-conversation):Visual Genome画像に基づく約9万件のマルチターン視覚質問応答会話。
- SakanaAI JA-VG-VQA-500 (SakanaAI/JA-VG-VQA-500):約1,500件の高品質日本語VQAサンプル。
LoRA構成: ランクr=64、alpha=128、言語モデルに適用。メモリ消費を管理するため、gradient checkpointingを有効化。
ハイパーパラメータ: 実効バッチサイズ256、1エポック、最大系列長2,048、bf16混合精度。
Phase 2: 推論強化
Phase 2では、金融数値分析に不可欠な数学的推論能力を強化する。本フェーズは言語モデルのみの操作であり(テキストのみの学習、視覚コンポーネントなし)。データセット作成の詳細な手順については、リポジトリの Phase 2 README を参照されたい。
2.1 SFT: 構造化推論のための知識蒸留
より強力な教師モデルからCompassへ、教師あり学習(SFT)により構造化された推論能力を蒸留する。
教師モデル: Qwen3-30B-A3B-Thinking-2507。強力な数学的推論能力を持つMixture-of-Experts(MoE)モデル。
データセット (Yana/ft-llm-2026-reasoning-sft):11種類の数学データセットから収集された約75万件の数学問題。教師モデルが構造化XMLフォーマットで解答を生成。本研究で構築したデータセット。
出力フォーマット: 問題理解、推論、最終解答を明示的に分離する構造化XMLフォーマットで応答を生成するよう訓練する:
<Problem>問題の自分の言葉での再記述</Problem>
<Thinking>中間計算を含む段階的推論過程</Thinking>
<Answer>\boxed{最終的な数値解答}</Answer>
この構造化フォーマットは推論過程を明示的に分解し、正確性の検証を容易にするとともに、多段階推論のどこでエラーが発生したかの特定を可能にする。
学習構成: メモリ要件を削減するためQLoRA [7](4-bit NF4量子化)を使用。LoRAランクr=32、alpha=64。効率的な学習のためTRL SFTTrainerをシーケンスパッキングと共に使用。
ハイパーパラメータ: 学習率2e-4、グローバルバッチサイズ64(マイクロバッチ2、勾配累積は64 / (2 x GPU数)で自動計算)、1エポック、最大系列長2,048、bf16混合精度。
Phase 3: ドメイン特化
Phase 3では、テキストベースの金融QAと直接的な視覚文書読解の二つの相補的アプローチにより、モデルを金融ドメインに適応させる。データセット作成の詳細な手順については、リポジトリの Phase 3 README を参照されたい。
3.1 テキストベース金融QA
本ステージでは、既存の金融QAベンチマークを用いてモデルに金融ドメイン知識を定着させる。
データセット:
- ConvFinQA [4]:約3,600件のマルチターン会話型金融QAインスタンス。金融表に対する逐次的な数値推論を要求。
- FinQA [5]:約8,000件のシングルターン質問。金融報告書に対する数値推論を要求し、解答導出のためのゴールドプログラム(DSL式)を含む。
- TAT-QA [8]:約16,500件の表形式とテキストのハイブリッド金融コンテンツに対する質問。スパン抽出、マルチスパン抽出、算術計算、カウントの4種類の回答タイプを網羅。
データ処理: 金融報告書の表形式データは[Header]...[Row N]マーカーを用いた線形化テキストフォーマットに変換。モデルは提供された金融コンテキストから質問解釈と解答の両方を生成するよう訓練される。
学習構成: 言語モデルのみ(視覚コンポーネントなし)。LoRAランクr=16、alpha=32。
ハイパーパラメータ: 学習率2e-5、実効バッチサイズ16(デバイスあたりバッチサイズ2、勾配累積8)、3エポック、最大系列長2,048、bf16混合精度。
3.2 VLMベース文書読解
最終ステージでは、金融文書画像を直接読み取り推論するよう訓練することで、視覚的文書理解とドメイン専門知識を統合する。
中核仮説: 実際の文書画像を処理することで、テキストのみの学習よりも深い文脈理解が得られる。モデルは表のフォーマット、グラフのレイアウト、文書構造などの視覚的手がかりを活用でき、これらはテキスト抽出では失われる。
データソース (Yana/ft-llm-2026-domain-specific-qa):以下の3つの日本政府機関の金融文書。本研究で構築したデータセットであり、本研究の主要な貢献の一つである:
- 内閣府
- 金融庁
- 財務省
質問生成: Qwen3-VL-32B/8Bが各ページについて4段階の難易度で3-5問を生成する:
| タイプ | 難易度 | 説明 | 例 |
|---|---|---|---|
| A | 易 | 数値抽出 | 表から特定の数値を読み取る |
| B | 中 | 変化率・比較 | 前年比成長率の計算 |
| C | 中-難 | 金融公式の適用 | 文書データからROE、WACC、PERを計算 |
| D | 難 | 多段階推論 | 約8ステップの推論を要する複雑な計算 |
視覚処理: PDFページはPyMuPDFを用いて150 DPIで画像にレンダリングされ、テキスト抽出をバイパスしてVLMに直接入力される。このアプローチは、JDocQAやEDINET_Benchなどのベンチマークが画像フォーマットの文書入力を使用する評価設定と一致する。
学習構成: 視覚エンコーダは凍結。MLPプロジェクタとLLM(LoRA r=16、alpha=32経由)を更新。
ハイパーパラメータ: 学習率2e-5、実効バッチサイズ16(デバイスあたりバッチサイズ2、勾配累積8)、3エポック、最大系列長2,048、bf16混合精度。
データセット
三段階の学習パイプラインで使用された全データセットを以下にまとめる:
| フェーズ | ステージ | データタイプ | 概算サイズ | ソース |
|---|---|---|---|---|
| 1 | 1-1 | 画像キャプション | ~330K | STAIR Captions [3](license_id=4、5キャプション/画像) |
| 1 | 1-1 | OCR | 生成 | Yana/ft-llm-2026-ocr-dataset ★ |
| 1 | 1-2 | VQA(抽出型+推論型) | 生成 | Yana/ft-llm-2026-qa-dataset ★ |
| 1 | 1-2 | VQA(マルチターン) | ~90K | ja-vg-vqa-conversation |
| 1 | 1-2 | VQA(高品質) | ~1.5K | SakanaAI JA-VG-VQA-500 |
| 2 | SFT | 数学(構造化推論) | ~750K | Yana/ft-llm-2026-reasoning-sft ★ |
| 3 | 3-1 | 金融QA(会話型) | ~3.6K | ConvFinQA [4] |
| 3 | 3-1 | 金融QA(数値推論) | ~8K | FinQA [5] |
| 3 | 3-1 | 金融QA(ハイブリッド) | ~16.5K | TAT-QA [8] |
| 3 | 3-2 | ドメインQA(視覚) | ~32K | Yana/ft-llm-2026-domain-specific-qa ★ |
★ = 本研究で構築したデータセット
実装の詳細
チャットテンプレート
Compassは全ての会話的インタラクションにllm-jp-4の指示フォーマットを使用する。テンプレート構造は以下の通り:
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。
### 指示:
{user_message}
### 応答:
{assistant_message}<|eos|>
システムメッセージ "以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。" が全ての会話の冒頭に付与される。特殊トークン<|eos|>(トークンID=2)が各アシスタントターンの終了を示す。学習時には、アシスタント応答トークン以外の全トークンがIGNORE_INDEX = -100でマスクされ、モデル生成コンテンツに対してのみ損失が計算される。
視覚入力に対しては、<image>トークンがプレースホルダとして機能し、フォワードパス時に視覚エンコーダの出力埋め込みに置換される。
ハイパーパラメータまとめ
| フェーズ | ステージ | 実効バッチ | エポック | 学習率 | 最大系列長 | LoRA構成 | 精度 |
|---|---|---|---|---|---|---|---|
| 1 | 1-1 | 128 | 2 | 1e-3 | 2,048 | なし(プロジェクタのみ) | bf16 |
| 1 | 1-2 | 256 | 1 | 2e-5(VE: 2e-6) | 2,048 | r=64, alpha=128 | bf16 |
| 2 | SFT | 64 | 1 | 2e-4 | 2,048 | r=32, alpha=64(QLoRA 4-bit) | bf16 |
| 3 | テキストQA | 16 | 3 | 2e-5 | 2,048 | r=16, alpha=32 | bf16 |
| 3 | ドメインQA | 16 | 3 | 2e-5 | 2,048 | r=16, alpha=32 | bf16 |
全フェーズでAdamWオプティマイザとウォームアップ付きコサイン学習率スケジューリングを使用。メモリ集約的なステージではgradient checkpointingを有効化。
評価設定
数学的推論と金融ドメイン理解にわたる3つのベンチマークスイートでCompassを評価する。結果は今後のアップデートで報告予定。
GSM8K(数学的推論)
GSM8K [9] は1,319問の英語の小学校算数文章題で構成され、多段階の算術推論をテストするよう設計されている。評価指標として完全一致精度を使用し、0-8ショットのchain-of-thoughtプロンプティングをサポートする。このベンチマークはPhase 2の推論強化の有効性を測定する。
JP Fin Harness(日本語金融知識)
JP Fin Harness は5つのタスクで構成される日本語金融ドメインの多肢選択式ベンチマークである:
| タスク | 説明 | 概算サイズ |
|---|---|---|
| chabsa | 金融センチメント分析 | ~800 |
| cma_basics | 証券アナリスト試験問題 | ~500 |
| cpa_audit | 公認会計士監査試験問題 | ~600 |
| fp2 | ファイナンシャルプランナー2級試験 | ~400 |
| security_sales_1 | 証券外務員試験 | ~300 |
評価指標は全タスクの正解率と、chabsaセンチメント分析タスクのマクロF1を含む。このベンチマークは、学習フェーズ全体を通じたモデルの金融ドメイン知識の保持と獲得を測定する。
EDINET Bench(複雑な金融タスク)
EDINET Bench [13] はEDINET(金融商品取引法に基づく有価証券報告書等の開示書類に関する電子開示システム)の提出書類から導出された複雑な金融タスクのパフォーマンスを評価する:
| タスク | タイプ | 説明 | 概算サイズ |
|---|---|---|---|
| fraud_detection | 二値分類 | 不正な金融報告の検出 | ~1,000 |
| earnings_forecast | 二値分類 | 業績方向の予測 | ~1,500 |
| industry_prediction | 多クラス(16クラス) | 企業の業種分類 | ~800 |
入力として、有価証券報告書から抽出したSummary(事業の概況)、BS(貸借対照表)、CF(キャッシュ・フロー計算書)、PL(損益計算書)の4セクションを使用する。このベンチマークは実際の金融文書の理解と分類能力をテストし、Phase 3のドメイン特化の有効性を直接的に測定する。
実験結果
学習損失
図2に、Compass学習パイプライン全フェーズの学習損失曲線を示す。
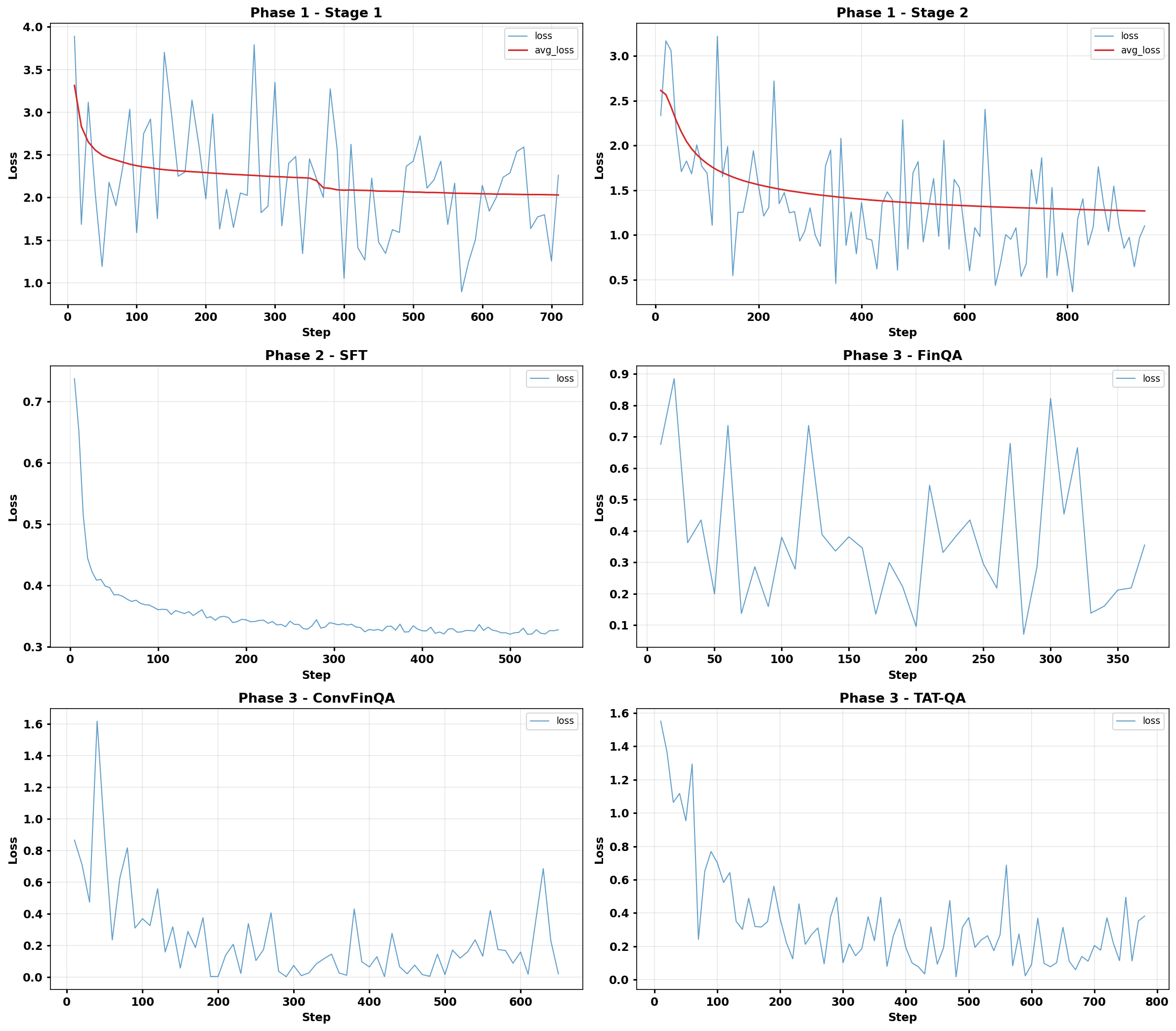
定量的結果
全タスクはzero-shot設定で評価した。以下の表に、各学習フェーズ終了時の性能と参考ベースラインを示す。
| ベンチマーク | Phase 1 | Phase 2 | Phase 3 Stage 1 | Phase 3 Stage 2 | Llama-3.3-70B [13] | Qwen-14B-Chat [14] |
|---|---|---|---|---|---|---|
| GSM-8K | 64.6 | 73.2 | — | 71.9 | — | 59.3 |
| EDINET Bench | ||||||
| earnings† | 0.532 | 0.500 | — | 0.458 | 0.41 | — |
| fraud† | 0.472 | 0.534 | — | 0.580 | 0.59 | — |
| industry | 8.5 | 6.9 | — | 6.5 | 14.0 | — |
| JP Fin Harness | 54.2 | 31.6 | 48.5 | 49.6 | — | 49.1 |
†ROC-AUC。その他はAccuracy(%)。太字はCompassの各フェーズ中の最良結果。—は未評価。Phase 3 Stage 1はStage 3-1(テキストベース金融QA)までの結果、Phase 3 Stage 2はStage 3-2(VLMベース文書読解)までの最終結果。
JP Fin Harness タスク別結果
| タスク | Phase 1 | Phase 2 | Phase 3 Stage 1 | Phase 3 Stage 2 |
|---|---|---|---|---|
| chabsa | 0.9428 | 0.5818 | 0.9357 | 0.9356 |
| cma_basics | 0.5526 | 0.2105 | 0.3947 | 0.3947 |
| cpa_audit | 0.2261 | 0.1683 | 0.2487 | 0.2362 |
| fp2 | 0.3389 | 0.1789 | 0.2863 | 0.2989 |
| security_sales_1 | 0.6491 | 0.4386 | 0.5614 | 0.6140 |
全タスクAccuracy。太字は各タスクの最良結果。
Phase 2の推論強化によりGSM-8Kが64.6から73.2に向上した一方、金融タスクの性能が大幅に低下した(JP Fin Harness: 54.2 → 31.6)。Phase 3のドメイン特化により金融タスク性能が49.6まで回復し、三段階アプローチの有効性が示された。注目すべきは、Phase 1モデルが既に強い金融知識を示していた点(JP Fin Harness: 54.2)であり、これは学習に使用した官公庁PDF文書に金融関連の情報が含まれていたためと考えられる。
定性的結果:Phase 1(視覚的指示理解)
Phase 1の学習後、Compassは日本語での視覚的質問の理解と回答が可能となった。
例1(正解 — 視覚的シーン理解):

指示: ここはどこですか
モデル応答: 動物園
正解: 動物園
例2(正解 — 人数カウント):
指示: 画像に写っている人の数はいくつですか?
モデル応答: 2人
正解: 2人
例3(不正解 — 文書詳細抽出):
指示: この資料のページ番号は何ですか?
モデル応答: 23
正解: 22
この誤りは、文書画像から正確な数値の詳細を抽出するには、後の学習フェーズでさらに精緻化される細粒度の視覚的注意が必要であることを示している。
定性的結果:Phase 2(数学的推論)
Phase 2の知識蒸留による学習後、Compassは構造化されたXMLフォーマットで推論を生成する。以下にGSM8Kの代表的な例を示す。
例1(正解):
問題: A robe takes 2 bolts of blue fiber and half that much white fiber. How many bolts in total does it take?
<Problem>
A robe takes 2 bolts of blue fiber and half that much white fiber.
How many bolts in total does it take?
</Problem>
<Thinking>
First, the problem states that a robe takes 2 bolts of blue fiber.
Then, "half that much white fiber" refers to the blue fiber,
so half of 2 bolts is 1 bolt of white fiber.
Total: 2 bolts (blue) + 1 bolt (white) = 3 bolts total.
</Thinking>
<Answer>
\boxed{3}
</Answer>
予測: 3 | 正解: 3 | 正答
例2(不正解):
問題: Josh decides to try flipping a house. He buys a house for $80,000 and then puts in $50,000 in repairs. This increased the value of the house by 150%. How much profit did he make?
<Problem>
Josh buys a house for $80,000 and puts in $50,000 in repairs.
This increased the value of the house by 150%.
How much profit did he make?
</Problem>
<Thinking>
Total cost: $80,000 + $50,000 = $130,000.
The repairs increased the value by 150% of the original value:
$80,000 × 1.5 = $120,000.
Profit: $120,000 - $130,000 = -$10,000...
</Thinking>
<Answer>
\boxed{0}
</Answer>
予測: 0 | 正解: 70,000 | 誤答
モデルは「increased the value by 150%」を誤解釈している。正しくは新しい価値が $80,000 + $80,000 × 1.5 = $200,000 となり、利益は $200,000 − $130,000 = $70,000 である。
例3(正解):
問題: Every day, Wendi feeds each of her chickens three cups of mixed chicken feed. She gives the chickens their feed in three separate meals. In the morning, she gives her flock of chickens 15 cups of feed. In the afternoon, she gives her chickens another 25 cups of feed. How many cups of feed does she need to give her chickens in the final meal of the day if the size of Wendi’s flock is 20 chickens?
<Problem>
Wendi feeds each of her 20 chickens 3 cups per day in 3 meals.
Morning: 15 cups. Afternoon: 25 cups.
How many cups for the final meal?
</Problem>
<Thinking>
Total feed given so far: 15 + 25 = 40 cups.
Total feed needed: 20 chickens × 3 cups = 60 cups.
Final meal: 60 - 40 = 20 cups.
</Thinking>
<Answer>
\boxed{20}
</Answer>
予測: 20 | 正解: 20 | 正答
まとめと今後の展望
Phase 2の推論強化により数学的推論が明確に向上し(GSM-8K: 64.6 → 73.2)、Phase 3のドメイン特化によりPhase 2で低下した金融タスク性能が回復した(JP Fin Harness: 31.6 → 49.6)。Phase 1モデルの強い初期的な金融性能(54.2)は、OCR・QAデータ生成に使用した官公庁PDF文書が既に十分な金融知識を含んでいることを示唆しており、この知識はPhase 2のテキストのみの推論学習で部分的に上書きされ、Phase 3の金融ファインチューニングで回復されたと考えられる。
EDINET Benchの不正会計検出タスクでは、Phase 3終了後にROC-AUC 0.580を達成し、8Bパラメータのモデルでありながらも上位のベースライン(Llama-3.3-70B: 0.59)に迫る結果となった。しかし、業種分類タスクは依然として困難(最良で8.5% vs. Llama-3.3-70Bの14.0%)であり、金融文書に対する多クラス分類の改善の余地がある。
現行モデルの主要なアーキテクチャ上の制約は、1回の推論で1画像のみを処理することである。実際の金融分析では、有価証券報告書内の複数ページの相互参照や異なる文書間での数値比較が頻繁に必要となる。Compassをマルチ画像入力に対応させることは、金融文書分析ワークフローにおける実用的なデプロイメントを実現するための重要な今後の方向性である。
謝辞
データセット作成に使用した金融文書は、財務省、金融庁および内閣府が公開する資料であり、公共データ利用規約(PDL-1.0)に基づき利用した。計算資源として、産総研およびAIST Solutionsが提供するABCI 3.0を利用した。
参考文献
[1] Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, Y., Bao, Y., Li, Z., Cui, C., & Li, Y. (2024). LLaVA-OneVision: Easy Visual Task Transfer. NeurIPS 2024.
[2] Qwen Team. (2025). Qwen3 Technical Report. arXiv preprint.
[3] Yoshikawa, Y., Shigeto, Y., & Takeuchi, A. (2017). STAIR Captions: Constructing a Large-Scale Japanese Image Caption Dataset. ACL 2017.
[4] Chen, Z., Li, S., Smiley, C., Ma, Z., Shah, S., & Wang, W. Y. (2022). ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering. EMNLP 2022.
[5] Chen, Z., Chen, W., Smiley, C., Shah, S., Borova, I., & Wang, W. Y. (2021). FinQA: A Dataset of Numerical Reasoning over Financial Data. EMNLP 2021.
[6] Zhai, X., Mustafa, B., Kolesnikov, A., & Beyer, L. (2023). Sigmoid Loss for Language Image Pre-Training. ICCV 2023.
[7] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized Language Models. NeurIPS 2023.
[8] Zhu, F., Lei, W., Huang, Y., Wang, C., Zhang, S., Lv, J., Feng, F., & Chua, T.-S. (2021). TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance. ACL 2021.
[9] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems. arXiv:2110.14168.
[10] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2022). LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022.
[11] Zhang, Y., Zhang, K., & Liang, X. (2024). LLaVAR-2: Large Language and Vision Assistant for Arbitrary-Resolution Image Understanding. arXiv:2412.16364.
[12] Zhang, Y., Zhang, R., Gu, J., Zhou, Y., Lipka, N., Yang, D., & Sun, T. (2023). LLaVAR: Enhanced Visual Instruction Tuning for Text-Rich Image Understanding. arXiv:2306.17107.
[13] Sugiura, I., Ishida, T., Makino, T., Tazuke, C., Nakagawa, T., Nakago, K., & Ha, D. (2026). EDINET-Bench: Evaluating LLMs on Complex Financial Tasks using Japanese Financial Statements. ICLR 2026. arXiv:2506.08762.
[14] Preferred Networks. japanese-lm-fin-harness. https://github.com/pfnet-research/japanese-lm-fin-harness
[15] Tschannen, M., Gritsenko, A., Narang, A., Zhai, X., & Beyer, L. (2025). SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features. arXiv:2502.14786.