GitHub Repository: https://github.com/AtsushiYanaigsawa768/Compass
HuggingFace Collection: https://huggingface.co/collections/Yana/compass
Poster: ft-lllm-2025-poster.pdf (Japanese)
Slide: ft-llm-2026-slide.pdf (Japanese)
This project was conducted as part of the free-form task of FT-LLM 2026.
Title: Development of a Japanese Financial VLM through Integration of Reasoning Enhancement and Document Comprehension (推論強化と文書読解の統合による日本語金融VLMの開発)
This research was carried out by Atsushi Yanagisawa and Genshin Kakimoto.
Introduction
The Japanese financial industry produces a vast volume of structured and semi-structured documents, including annual securities reports (有価証券報告書), earnings summaries (決算短信), and regulatory filings from agencies such as the Financial Services Agency (FSA) and the Ministry of Finance (MOF). These documents present unique challenges for automated understanding: complex table layouts interleaving numerical data with prose, mixed Japanese-English notation, and the need for multi-step numerical reasoning over domain-specific financial concepts such as ROE, WACC, and year-over-year growth rates.
While recent Vision-Language Models (VLMs) have demonstrated strong performance on general-purpose visual question answering and document understanding tasks [1], their application to Japanese financial documents remains limited. General-purpose VLMs lack the domain-specific reasoning capability required to interpret financial tables and perform accurate numerical computations, and most existing models are optimized for English-language content.
In this work, we present Compass, a Japanese financial VLM that addresses these challenges through a three-phase training pipeline integrating: (1) foundation-level vision-language alignment, (2) mathematical reasoning enhancement via knowledge distillation, and (3) financial domain specialization through direct visual document reading. Our model is built on the LLaVA-OneVision architecture [1] with several key adaptations for the Japanese financial domain, including the use of llm-jp-4-8b as the language backbone and a custom chat template designed for instruction following in Japanese.
Our main contributions are:
- A three-phase training pipeline that progressively builds vision-language alignment, structured mathematical reasoning, and financial domain expertise.
- Knowledge distillation from Qwen3-30B-A3B-Thinking-2507 [2] using XML-structured output format, enabling structured step-by-step reasoning over approximately 750K mathematical problems.
- Construction of document understanding datasets from Japanese government PDF documents (Cabinet Office, FSA, MOF) for both Phase 1 (OCR and visual QA data) and Phase 3 (financial domain QA with multi-difficulty questions and consistency verification). These datasets are publicly available on HuggingFace and represent a major contribution of this work.
- Direct visual document reading of Japanese government financial PDFs rendered at 150 DPI, covering four difficulty levels of financial question answering.
Architecture
Compass follows the three-component VLM architecture established by LLaVA-OneVision [1], consisting of a vision encoder, an MLP projector, and a large language model. We adopt specific components tailored for Japanese financial document understanding.
Vision Encoder
We employ SigLIP-v2 SO400M-patch14-384 [6, 15] as the vision encoder. This model produces feature representations with a hidden dimension of 1,152 and generates 729 patches per image (27 x 27 spatial grid from 384 x 384 input resolution at patch size 14). We extract features from the second-to-last layer (layer -2), following the convention established in LLaVA-OneVision.
MLP Projector
The vision-language projector is a two-layer MLP that maps vision encoder outputs to the language model’s embedding space:
Linear(1152 → 4096) → GELU → Linear(4096 → 4096)
The projector contains approximately 8M trainable parameters and serves as the primary bridge between visual and linguistic representations.
Language Model
We use llm-jp-4-8b as the language backbone, an 8-billion-parameter Japanese language model with a hidden dimension of 4,096. This is a key departure from the original LLaVA-OneVision, which uses Vicuna or LLaMA-based models. The choice of llm-jp-4-8b is motivated by its strong pre-training on Japanese text corpora, which provides a more suitable foundation for Japanese financial document understanding.
Key Differences from LLaVA-OneVision
Unlike LLaVA-OneVision, Compass does not adopt the AnyRes multi-resolution processing strategy. While LLaVA-OneVision uses AnyRes-9 (1 global crop + up to 8 local crops, producing 6,561 vision tokens per image), Compass processes each input image as a single 384 x 384 crop, producing 729 vision tokens per image. This design choice reduces computational cost while maintaining sufficient resolution for document understanding tasks.
| Aspect | LLaVA-OneVision | Compass |
|---|---|---|
| Multi-Resolution | AnyRes-9 (6,561 tokens/image) | Single crop (729 tokens/image) |
| Stage 1-1 Epochs | 1 | 2 (compensating for smaller dataset: 330K vs 558K) |
| Stage 1-2 LLM Training | Full fine-tuning | LoRA (r=64, alpha=128) |
| Effective Batch (Stage 1-1) | 256 | 128 |
Training Pipeline
Our training pipeline consists of three phases, each designed to build upon the capabilities established in previous phases. The following table summarizes the module training states across all phases:
| Phase | Stage | Vision Encoder | MLP Projector | LLM | Objective |
|---|---|---|---|---|---|
| Phase 1 | Stage 1-1 | Frozen | Train | Frozen | Vision-language alignment |
| Phase 1 | Stage 1-2 | Train | Train | LoRA (r=64) | Visual instruction following |
| Phase 2 | SFT | — | — | QLoRA (r=32) | Structured reasoning |
| Phase 3 | Stage 3-1 | — | — | LoRA (r=16) | Financial text QA |
| Phase 3 | Stage 3-2 | Frozen | Train | LoRA (r=16) | Financial document reading |
Frozen = parameters fixed; Train = parameters updated; — = module not used.
Phase 1: Foundation VLM Development
Phase 1 establishes the fundamental vision-language alignment and visual instruction-following capability. For detailed dataset creation procedures, see the Phase 1 README in the repository.
Stage 1-1: Caption and OCR Pre-training
The objective of this stage is to establish basic vision-language correspondence by training the MLP projector to align visual features with the language model’s embedding space.
Training configuration: Only the MLP projector is updated; both the vision encoder and language model remain frozen.
Datasets:
- STAIR Captions (shunk031/STAIR-Captions) [3]: Approximately 330K Japanese image-caption pairs (filtered to license_id=4). Each image has 5 associated captions, and we randomly sample one caption per image during each training epoch to increase data diversity.
- OCR Dataset (Yana/ft-llm-2026-ocr-dataset): Generated from Japanese government PDF documents using Qwen3-VL-32B with 4 types of OCR prompts, inspired by LLaVAR [12]. This dataset teaches the model to read text from document images. This dataset was constructed as part of this research.
Training prompt: Each sample uses the instruction "この画像を端的に説明してください。" (Describe this image briefly.) for caption data, with the corresponding caption as the target response.
Hyperparameters: Learning rate 1e-3 with AdamW optimizer, cosine learning rate scheduler with 3% warmup, effective batch size 128 (per-device batch 2, gradient accumulation 64), 2 epochs, maximum sequence length 2,048, bf16 mixed precision. The loss function is cross-entropy loss (next-token prediction), computed only over response tokens.
Stage 1-2: Visual Instruction Tuning
This stage enables the model to understand and follow visual instructions by training all three components.
Training configuration: The vision encoder, MLP projector, and language model (via LoRA) are all updated. The vision encoder uses a reduced learning rate of 2e-6 to preserve pre-trained visual features, while the projector and LLM LoRA use 2e-5.
Datasets:
- QA Dataset (Yana/ft-llm-2026-qa-dataset): Question-answer pairs generated by Qwen3-VL using a two-stage process: first extractive QA (De), then reasoning QA (Dr), from government PDF pages. The format was inspired by LLaVAR-2 [11]. This dataset was constructed as part of this research.
- ja-vg-vqa-conversation (llm-jp/ja-vg-vqa-conversation): Approximately 90K multi-turn visual question answering conversations based on Visual Genome images.
- SakanaAI JA-VG-VQA-500 (SakanaAI/JA-VG-VQA-500): Approximately 1,500 high-quality Japanese VQA samples.
LoRA configuration: Rank r=64, alpha=128, applied to the language model. Gradient checkpointing is enabled to manage memory consumption.
Hyperparameters: Effective batch size 256, 1 epoch, maximum sequence length 2,048, bf16 mixed precision.
Phase 2: Reasoning Enhancement
Phase 2 strengthens the model’s mathematical reasoning capability, which is critical for financial numerical analysis. This phase operates on the language model only (text-only training, no vision components). For detailed dataset creation procedures, see the Phase 2 README in the repository.
2.1 SFT: Knowledge Distillation for Structured Reasoning
We distill structured reasoning capability from a stronger teacher model into Compass using supervised fine-tuning (SFT).
Teacher model: Qwen3-30B-A3B-Thinking-2507, a Mixture-of-Experts (MoE) model with strong mathematical reasoning capability.
Dataset (Yana/ft-llm-2026-reasoning-sft): Approximately 750K mathematical problems drawn from 11 diverse math datasets, with teacher-generated solutions in a structured XML format. This dataset was constructed as part of this research.
Output format: We train the model to produce responses in a structured XML format that separates problem understanding, reasoning, and final answer:
<Problem>Restatement of the problem in the model's own words</Problem>
<Thinking>Step-by-step reasoning process with intermediate calculations</Thinking>
<Answer>\boxed{final numerical answer}</Answer>
This structured format explicitly decomposes the reasoning process, making it easier to verify correctness and identify where errors occur in multi-step reasoning.
Training configuration: QLoRA [7] with 4-bit NF4 quantization to reduce memory requirements. LoRA rank r=32, alpha=64. TRL SFTTrainer with sequence packing is used for efficient training.
Hyperparameters: Learning rate 2e-4, global batch size 64 (micro batch 2, gradient accumulation auto-calculated as 64 / (2 x num_gpus)), 1 epoch, maximum sequence length 2,048, bf16 mixed precision.
Phase 3: Domain Specialization
Phase 3 adapts the model to the financial domain through two complementary approaches: text-based financial QA and direct visual document reading. For detailed dataset creation procedures, see the Phase 3 README in the repository.
3.1 Text-Based Financial QA
This stage grounds the model in financial domain knowledge using established financial QA benchmarks.
Datasets:
- ConvFinQA [4]: Approximately 3,600 multi-turn conversational financial QA instances requiring sequential numerical reasoning over financial tables.
- FinQA [5]: Approximately 8,000 single-turn questions requiring numerical reasoning over financial reports, with gold programs (DSL expressions) for answer derivation.
- TAT-QA [8]: Approximately 16,500 questions over hybrid tabular-textual financial content, covering four answer types: span extraction, multi-span extraction, arithmetic computation, and counting.
Data processing: Tabular data from financial reports is converted to a linearized text format using [Header]...[Row N] markers. The model is trained to generate both the question interpretation and the answer from the provided financial context.
Training configuration: Language model only (no vision components). LoRA rank r=16, alpha=32.
Hyperparameters: Learning rate 2e-5, effective batch size 16 (per-device batch 2, gradient accumulation 8), 3 epochs, maximum sequence length 2,048, bf16 mixed precision.
3.2 VLM-Based Document Reading
The final stage integrates visual document understanding with domain expertise by training the model to directly read and reason about financial document images.
Core hypothesis: Processing actual document images yields deeper contextual understanding than text-only learning, as the model can leverage visual cues such as table formatting, graph layouts, and document structure that are lost in text extraction.
Data source (Yana/ft-llm-2026-domain-specific-qa): Financial documents from three Japanese government agencies. This dataset was constructed as part of this research and represents a major contribution of this work:
- Cabinet Office (内閣府)
- Financial Services Agency (金融庁)
- Ministry of Finance (財務省)
Question generation: Qwen3-VL-32B/8B generates 3-5 questions per page across four difficulty levels:
| Type | Difficulty | Description | Example |
|---|---|---|---|
| A | Easy | Numerical extraction | Read specific figures from tables |
| B | Medium | Rate of change / comparison | Calculate year-over-year growth rates |
| C | Medium-Hard | Financial formula application | Calculate ROE, WACC, PER from document data |
| D | Hard | Multi-step reasoning | Complex calculations requiring ~8 reasoning steps |
Visual processing: PDF pages are rendered to images at 150 DPI using PyMuPDF and input directly to the VLM, bypassing text extraction. This approach aligns with the evaluation setting, as benchmarks such as JDocQA and EDINET_Bench use image-format document input.
Training configuration: Vision encoder frozen; MLP projector and LLM (via LoRA r=16, alpha=32) are updated.
Hyperparameters: Learning rate 2e-5, effective batch size 16 (per-device batch 2, gradient accumulation 8), 3 epochs, maximum sequence length 2,048, bf16 mixed precision.
Datasets
The following table summarizes all datasets used across the three training phases:
| Phase | Stage | Data Type | Approximate Size | Source |
|---|---|---|---|---|
| 1 | 1-1 | Image Captions | ~330K | STAIR Captions [3] (license_id=4, 5 captions/image) |
| 1 | 1-1 | OCR | Generated | Yana/ft-llm-2026-ocr-dataset ★ |
| 1 | 1-2 | VQA (extractive + reasoning) | Generated | Yana/ft-llm-2026-qa-dataset ★ |
| 1 | 1-2 | VQA (multi-turn) | ~90K | ja-vg-vqa-conversation |
| 1 | 1-2 | VQA (high-quality) | ~1.5K | SakanaAI JA-VG-VQA-500 |
| 2 | SFT | Math (structured reasoning) | ~750K | Yana/ft-llm-2026-reasoning-sft ★ |
| 3 | 3-1 | Financial QA (conversational) | ~3.6K | ConvFinQA [4] |
| 3 | 3-1 | Financial QA (numerical) | ~8K | FinQA [5] |
| 3 | 3-1 | Financial QA (hybrid) | ~16.5K | TAT-QA [8] |
| 3 | 3-2 | Domain QA (visual) | ~32K | Yana/ft-llm-2026-domain-specific-qa ★ |
★ = Dataset constructed as part of this research.
Implementation Details
Chat Template
Compass uses the llm-jp-4 instruction format for all conversational interactions. The template structure is:
以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。
### 指示:
{user_message}
### 応答:
{assistant_message}<|eos|>
The system message "以下は、タスクを説明する指示です。要求を適切に満たす応答を書きなさい。" is prepended to all conversations. The special token <|eos|> (token id=2) marks the end of each assistant turn. During training, all tokens except assistant response tokens are masked with IGNORE_INDEX = -100 to ensure the loss is computed only over model-generated content.
For vision inputs, the <image> token serves as a placeholder that is replaced by the vision encoder’s output embeddings during forward pass.
Hyperparameter Summary
| Phase | Stage | Effective Batch | Epochs | Learning Rate | Max Seq Len | LoRA Config | Precision |
|---|---|---|---|---|---|---|---|
| 1 | 1-1 | 128 | 2 | 1e-3 | 2,048 | None (projector only) | bf16 |
| 1 | 1-2 | 256 | 1 | 2e-5 (VE: 2e-6) | 2,048 | r=64, alpha=128 | bf16 |
| 2 | SFT | 64 | 1 | 2e-4 | 2,048 | r=32, alpha=64 (QLoRA 4-bit) | bf16 |
| 3 | Text QA | 16 | 3 | 2e-5 | 2,048 | r=16, alpha=32 | bf16 |
| 3 | Domain QA | 16 | 3 | 2e-5 | 2,048 | r=16, alpha=32 | bf16 |
All phases use AdamW optimizer with cosine learning rate scheduling and warmup. Gradient checkpointing is enabled for memory-intensive stages.
Evaluation Setup
We evaluate Compass on three benchmark suites spanning mathematical reasoning and financial domain understanding. Results will be reported in a forthcoming update.
GSM8K (Mathematical Reasoning)
GSM8K [9] consists of 1,319 grade school math word problems in English, designed to test multi-step arithmetic reasoning. We use exact match accuracy as the evaluation metric, with support for 0-8 shot chain-of-thought prompting. This benchmark measures the effectiveness of Phase 2 reasoning enhancement.
JP Fin Harness (Japanese Financial Knowledge)
JP Fin Harness is a Japanese financial domain multiple-choice benchmark comprising five tasks:
| Task | Description | Approx. Size |
|---|---|---|
| chabsa | Financial sentiment analysis | ~800 |
| cma_basics | Securities analyst exam questions | ~500 |
| cpa_audit | CPA audit exam questions | ~600 |
| fp2 | Financial planner level 2 exam | ~400 |
| security_sales_1 | Securities sales representative exam | ~300 |
Evaluation metrics include accuracy across all tasks and macro F1 for the chabsa sentiment analysis task. This benchmark measures the model’s retention and acquisition of financial domain knowledge across training phases.
EDINET Bench (Complex Financial Tasks)
EDINET Bench [13] evaluates performance on complex financial tasks derived from EDINET (Electronic Disclosure for Investors’ NETwork) filings:
| Task | Type | Description | Approx. Size |
|---|---|---|---|
| fraud_detection | Binary classification | Detecting fraudulent financial reports | ~1,000 |
| earnings_forecast | Binary classification | Predicting earnings direction | ~1,500 |
| industry_prediction | Multi-class (16 classes) | Classifying company industry sector | ~800 |
The input consists of four sections extracted from annual securities reports: Summary (business overview), BS (balance sheet), CF (cash flow statement), and PL (profit and loss statement). This benchmark tests the model’s ability to understand and classify real financial documents, directly measuring the effectiveness of Phase 3 domain specialization.
Experimental Results
Training Loss
Figure 2 shows the training loss curves across all phases of the Compass training pipeline.
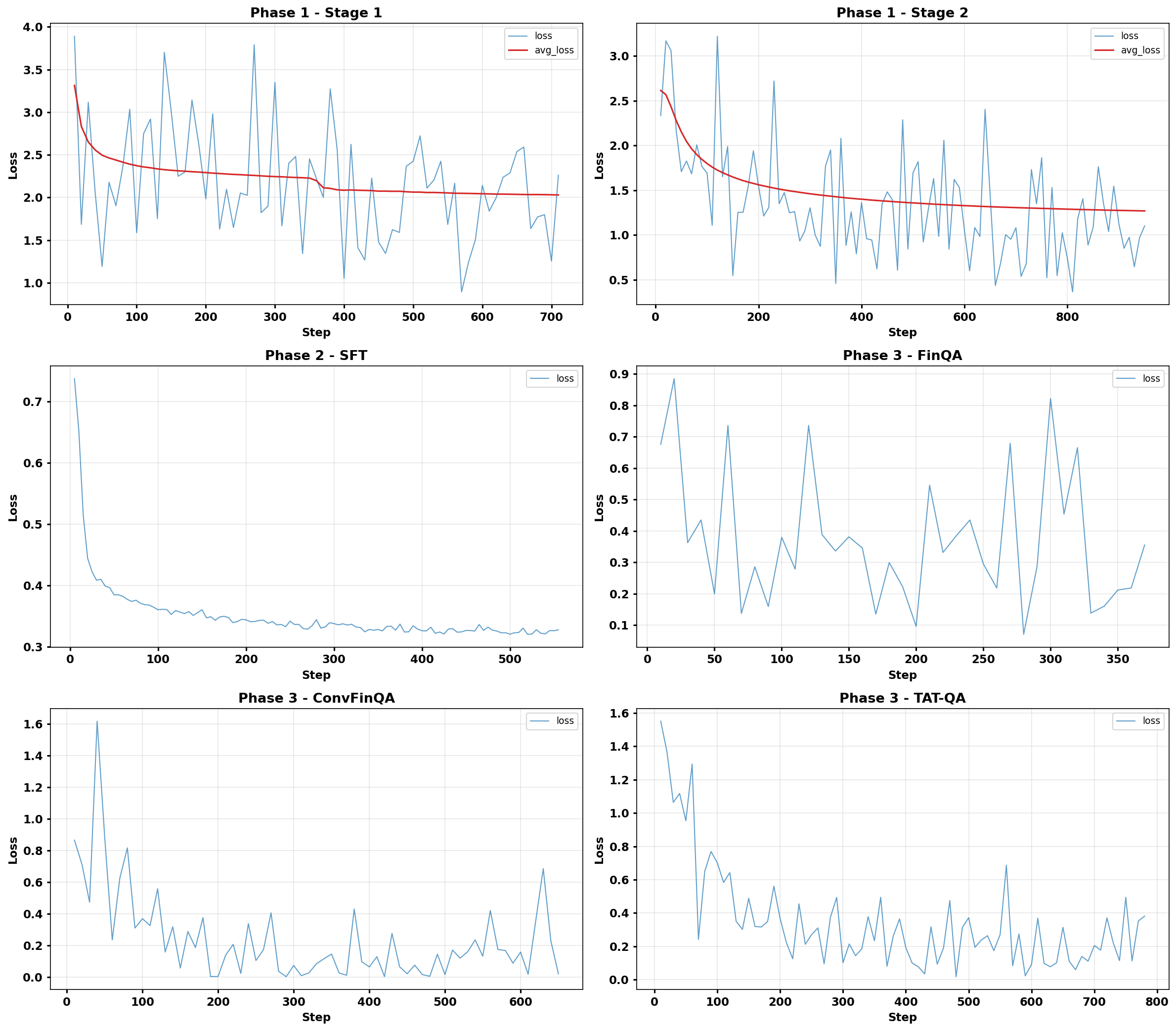
Quantitative Results
All tasks are evaluated in a zero-shot setting. The following table shows performance at the end of each training phase, along with reference baselines.
| Benchmark | Phase 1 | Phase 2 | Phase 3 Stage 1 | Phase 3 Stage 2 | Llama-3.3-70B [13] | Qwen-14B-Chat [14] |
|---|---|---|---|---|---|---|
| GSM-8K | 64.6 | 73.2 | — | 71.9 | — | 59.3 |
| EDINET Bench | ||||||
| earnings† | 0.532 | 0.500 | — | 0.458 | 0.41 | — |
| fraud† | 0.472 | 0.534 | — | 0.580 | 0.59 | — |
| industry | 8.5 | 6.9 | — | 6.5 | 14.0 | — |
| JP Fin Harness | 54.2 | 31.6 | 48.5 | 49.6 | — | 49.1 |
†ROC-AUC. All others are Accuracy (%). Bold indicates the best result among Compass phases. — indicates not evaluated. Phase 3 Stage 1 refers to the model after Stage 3-1 (text-based financial QA) only; Phase 3 Stage 2 is the final result after Stage 3-2 (VLM-based document reading).
JP Fin Harness Per-Task Results
| Task | Phase 1 | Phase 2 | Phase 3 Stage 1 | Phase 3 Stage 2 |
|---|---|---|---|---|
| chabsa | 0.9428 | 0.5818 | 0.9357 | 0.9356 |
| cma_basics | 0.5526 | 0.2105 | 0.3947 | 0.3947 |
| cpa_audit | 0.2261 | 0.1683 | 0.2487 | 0.2362 |
| fp2 | 0.3389 | 0.1789 | 0.2863 | 0.2989 |
| security_sales_1 | 0.6491 | 0.4386 | 0.5614 | 0.6140 |
All tasks report Accuracy. Bold indicates the best result per task.
Phase 2 reasoning enhancement improved GSM-8K from 64.6 to 73.2, but significantly degraded financial task performance (JP Fin Harness: 54.2 → 31.6). Phase 3 domain specialization recovered financial performance to 49.6, demonstrating the effectiveness of the three-phase approach. Notably, the Phase 1 model already exhibited strong financial knowledge (JP Fin Harness: 54.2), likely due to financial content present in the government PDF documents used during training.
Qualitative Results: Phase 1 (Visual Instruction Following)
After Phase 1 training, Compass demonstrates the ability to understand and respond to visual questions in Japanese.
Example 1 (Correct — Visual Scene Understanding):

Instruction: ここはどこですか(Where is this place?)
Model Response: 動物園(Zoo)
Ground Truth: 動物園(Zoo)
Example 2 (Correct — Counting):
Instruction: 画像に写っている人の数はいくつですか?(How many people are in the image?)
Model Response: 2人(2 people)
Ground Truth: 2人(2 people)
Example 3 (Incorrect — Document Detail Extraction):
Instruction: この資料のページ番号は何ですか?(What is the page number of this document?)
Model Response: 23
Ground Truth: 22
This error illustrates a common challenge: extracting precise numerical details from document images requires fine-grained visual attention that is further refined in later training phases.
Qualitative Results: Phase 2 (Mathematical Reasoning)
After Phase 2 training with knowledge distillation, Compass generates structured XML-formatted reasoning. Below are representative GSM8K examples.
Example 1 (Correct):
Question: A robe takes 2 bolts of blue fiber and half that much white fiber. How many bolts in total does it take?
<Problem>
A robe takes 2 bolts of blue fiber and half that much white fiber.
How many bolts in total does it take?
</Problem>
<Thinking>
First, the problem states that a robe takes 2 bolts of blue fiber.
Then, "half that much white fiber" refers to the blue fiber,
so half of 2 bolts is 1 bolt of white fiber.
Total: 2 bolts (blue) + 1 bolt (white) = 3 bolts total.
</Thinking>
<Answer>
\boxed{3}
</Answer>
Predicted: 3 | Reference: 3 | Correct
Example 2 (Incorrect):
Question: Josh decides to try flipping a house. He buys a house for $80,000 and then puts in $50,000 in repairs. This increased the value of the house by 150%. How much profit did he make?
<Problem>
Josh buys a house for $80,000 and puts in $50,000 in repairs.
This increased the value of the house by 150%.
How much profit did he make?
</Problem>
<Thinking>
Total cost: $80,000 + $50,000 = $130,000.
The repairs increased the value by 150% of the original value:
$80,000 × 1.5 = $120,000.
Profit: $120,000 - $130,000 = -$10,000...
</Thinking>
<Answer>
\boxed{0}
</Answer>
Predicted: 0 | Reference: 70,000 | Incorrect
The model misinterprets “increased the value by 150%” — the correct interpretation is that the new value is $80,000 + $80,000 × 1.5 = $200,000, yielding a profit of $200,000 − $130,000 = $70,000.
Example 3 (Correct):
Question: Every day, Wendi feeds each of her chickens three cups of mixed chicken feed. She gives the chickens their feed in three separate meals. In the morning, she gives her flock of chickens 15 cups of feed. In the afternoon, she gives her chickens another 25 cups of feed. How many cups of feed does she need to give her chickens in the final meal of the day if the size of Wendi’s flock is 20 chickens?
<Problem>
Wendi feeds each of her 20 chickens 3 cups per day in 3 meals.
Morning: 15 cups. Afternoon: 25 cups.
How many cups for the final meal?
</Problem>
<Thinking>
Total feed given so far: 15 + 25 = 40 cups.
Total feed needed: 20 chickens × 3 cups = 60 cups.
Final meal: 60 - 40 = 20 cups.
</Thinking>
<Answer>
\boxed{20}
</Answer>
Predicted: 20 | Reference: 20 | Correct
Conclusion and Future Work
Phase 2 reasoning enhancement yielded a clear improvement in mathematical reasoning (GSM-8K: 64.6 → 73.2), while Phase 3 domain specialization recovered financial task performance that had degraded during Phase 2 (JP Fin Harness: 31.6 → 49.6). The Phase 1 model’s strong initial financial performance (54.2) suggests that government PDF documents used for OCR and QA data generation already contain substantial financial knowledge, which was partially overwritten during text-only reasoning training in Phase 2 and subsequently recovered through targeted financial fine-tuning in Phase 3.
For the EDINET Bench fraud detection task, Compass achieved an ROC-AUC of 0.580 after Phase 3, approaching the Llama-3.3-70B baseline (0.59) despite having only 8B parameters. However, the industry prediction task remains challenging (8.5% at best vs. 14.0% for Llama-3.3-70B), indicating room for improvement in multi-class classification over financial documents.
A key architectural limitation of the current model is that it processes only one image per inference call. Real-world financial analysis frequently requires cross-referencing multiple pages within a securities report or comparing figures across different documents. Extending Compass to support multi-image input is a critical direction for future work to enable practical deployment in financial document analysis workflows.
Acknowledgments
The financial documents used for dataset construction are publicly available materials from the Ministry of Finance (MOF), the Financial Services Agency (FSA), and the Cabinet Office, and were used in accordance with the Government of Japan Standard Terms of Use (PDL-1.0). Computational resources were provided by ABCI 3.0, operated by the National Institute of Advanced Industrial Science and Technology (AIST) and AIST Solutions.
References
[1] Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, Y., Bao, Y., Li, Z., Cui, C., & Li, Y. (2024). LLaVA-OneVision: Easy Visual Task Transfer. NeurIPS 2024.
[2] Qwen Team. (2025). Qwen3 Technical Report. arXiv preprint.
[3] Yoshikawa, Y., Shigeto, Y., & Takeuchi, A. (2017). STAIR Captions: Constructing a Large-Scale Japanese Image Caption Dataset. ACL 2017.
[4] Chen, Z., Li, S., Smiley, C., Ma, Z., Shah, S., & Wang, W. Y. (2022). ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering. EMNLP 2022.
[5] Chen, Z., Chen, W., Smiley, C., Shah, S., Borova, I., & Wang, W. Y. (2021). FinQA: A Dataset of Numerical Reasoning over Financial Data. EMNLP 2021.
[6] Zhai, X., Mustafa, B., Kolesnikov, A., & Beyer, L. (2023). Sigmoid Loss for Language Image Pre-Training. ICCV 2023.
[7] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient Finetuning of Quantized Language Models. NeurIPS 2023.
[8] Zhu, F., Lei, W., Huang, Y., Wang, C., Zhang, S., Lv, J., Feng, F., & Chua, T.-S. (2021). TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance. ACL 2021.
[9] Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., & Schulman, J. (2021). Training Verifiers to Solve Math Word Problems. arXiv:2110.14168.
[10] Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., & Chen, W. (2022). LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022.
[11] Zhang, Y., Zhang, K., & Liang, X. (2024). LLaVAR-2: Large Language and Vision Assistant for Arbitrary-Resolution Image Understanding. arXiv:2412.16364.
[12] Zhang, Y., Zhang, R., Gu, J., Zhou, Y., Lipka, N., Yang, D., & Sun, T. (2023). LLaVAR: Enhanced Visual Instruction Tuning for Text-Rich Image Understanding. arXiv:2306.17107.
[13] Sugiura, I., Ishida, T., Makino, T., Tazuke, C., Nakagawa, T., Nakago, K., & Ha, D. (2026). EDINET-Bench: Evaluating LLMs on Complex Financial Tasks using Japanese Financial Statements. ICLR 2026. arXiv:2506.08762.
[14] Preferred Networks. japanese-lm-fin-harness. https://github.com/pfnet-research/japanese-lm-fin-harness
[15] Tschannen, M., Gritsenko, A., Narang, A., Zhai, X., & Beyer, L. (2025). SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features. arXiv:2502.14786.